
不露脸也能做短视频,这个需求最近越来越多人提。以前想做数字人,要么花几千块找外包,要么折腾复杂的软件。现在即梦AI把这个门槛砍到了零。一张照片、一段音频,几分钟就能出一个效果不错的数字人口播视频。

凌创派的这篇文章会把操作方法掰开揉碎讲清楚。先说说这个工具靠什么技术,再手把手带你走一遍完整的制作流程。
字节跳动悄悄放了个大招
即梦AI是字节跳动旗下的一站式AI创作平台,网址是 jimeng.jianying.com。它在2025年3月7日正式上线了数字人功能的"大师模式",背后驱动技术是字节自研的 OmniHuman-1 模型(雷锋网,2025年3月7日报道)。
这个模型做的事情很简单。一张图片加一段音频,就能让图片里的人活过来。嘴型对得上、表情跟得上、身体还会动。真人照片能用,动漫角色、3D卡通形象也没问题。
说起来简单,但实操中有不少坑。下面是我自己测试下来总结的完整流程,每一步都踩过坑。
第一步:准备工作,决定成败
80%的翻车案例都卡在这一步。
照片选对,后面省一半事
合适的照片长这样:
- 分辨率够高,五官清晰可见
- 自然光或者柔光拍摄,别用闪光灯直打
- 头肩比例大概 1:2
- 表情自然,微笑或者平静都可以
- 正面或者微侧(不超过15度)
- 背景干净,最好是纯色
千万别用的照片:
- 大角度俯拍、仰拍
- 浓妆艳抹的艺术照
- 脸上有强烈阴影
- 模糊的手机截图
- 背景杂乱的街拍
选错照片会出现什么后果?嘴型对不上、面部抖动、动作变形、背景穿帮。基本上就是"崩坏"现场。
音频怎么准备
音频的质量直接影响数字人的自然度。三个办法:
- 直接打字:在即梦的"文本朗读"框里输入文案,选一个喜欢的音色,系统会自动合成语音
- 上传录音:自己录好的MP3文件传上去,效果最好
- 声音克隆:上传5秒以上的音频素材,生成专属音色(腾讯新闻实测,2025年3月)
不管用哪种方式,记住一个原则。音频越干净,数字人越自然。背景音、回声、环境噪音都会让数字人看起来违和。
第二步:进入操作页面
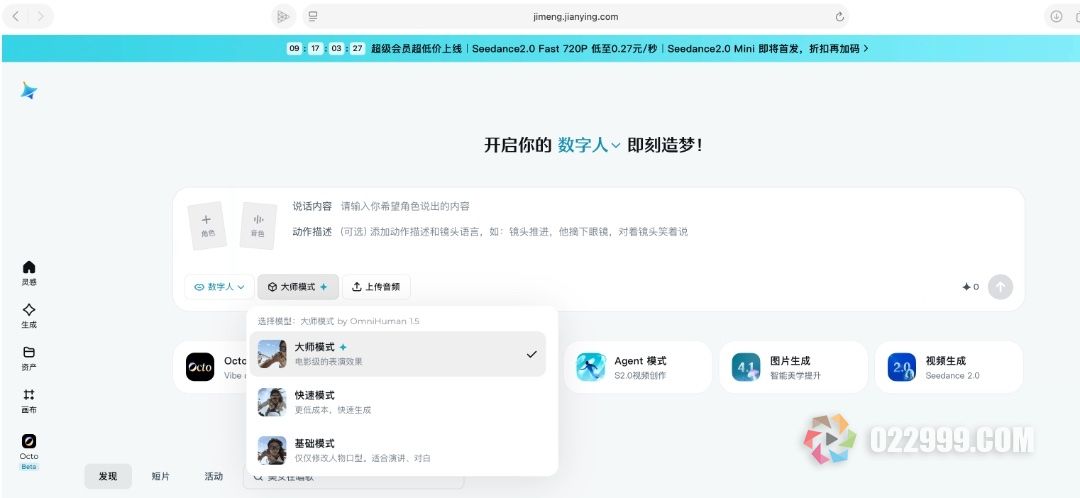
打开即梦AI官网(jimeng.jianying.com),登录你的账号。左侧边栏找到"灵感",中间的下拉菜单第一项选"数字人",第二项选“大师模式”。
第三步:上传素材,开始生成
操作顺序很简单。先传音频,再传图片。
传音频:点击"上传音频",选你准备好的MP3文件。也可以用"文本转音频",直接输入台词,选音色和语速。想要声音克隆效果的,点"声音克隆",上传录音就行。
传图片:音频传好后,点"上传素材",选你的照片或者图片。系统会自动识别图片里的人物,识别不准的话可以手动框选。
选模式:这里最关键。即梦提供了三种生成效果,区别很大:
| 模式 | 效果特点 | 适合场景 | 积分消耗 |
|---|---|---|---|
| 标准模式 | 基础对口型,画面简单 | 快速测试、预览效果 | 较低 |
| 生动模式 | 口型匹配+面部微表情 | 一般口播视频 | 中等 |
| 大师模式 | 全身动作+背景动效+表情同步,最逼真 | 品牌宣传、专业内容 | 每秒约8积分 |
大师模式基于OmniHuman-1.5模型,效果是三个里面最好的。不光嘴型对得上,人物的手势、身体动作、甚至背景里的光影都会动起来。目前音频最长支持15秒。
第四步:调整参数,别踩这几个坑
选了大师模式之后,有几个参数值得调一下:
运动幅度:建议调到 2到3 之间。调太高的话,人物脑袋晃得像拨浪鼓,画面会崩。我们追求的是"嘴在动"而不是"头在晃"。
口型匹配模式:新手优先选"生动模式",既对准口型又能同步面部微表情。要做商业级效果就选"大师模式"。
画质:直接选 1080P,免费版也能用。
第五步:预览和导出
参数调好后点"生成视频",等10到30秒就能看到效果。
预览时重点看三个地方:
- 口型:和音频对得上吗?有错位就换音频片段重试
- 表情:自然吗?太僵硬就切到生动模式
- 动作:会不会太夸张?运动幅度调低点
没问题就点"导出",选MP4格式。导出来的视频可以在剪映里加字幕、配乐,也可以直接发抖音、小红书。
积分怎么算,到底要不要花钱?
即梦AI用积分制。免费用户每天可以领 60到100个积分,每天刷新。大师模式每秒消耗8积分。算下来,一天免费积分够生成10秒左右的视频。
如果想多做一些,可以买会员。即梦的会员分几个档次:
| 会员类型 | 月赠送积分 | 主要权益 |
|---|---|---|
| 基础会员 | 一定额度 | 去水印、优先排队、每月赠送积分 |
| 标准会员 | 更高额度 | 基础权益+更多积分 |
| 高级会员 | 最高额度 | 全部权益+最多积分 |
日常轻度使用的话,每天的免费积分基本够用(来源:即梦AI付费服务协议)。
几个常见问题
Q:能用在商业项目里吗?
A:可以,付费版支持商业用途。免费版生成的内容有水印。
Q:动漫图片能用吗?
A:能用。OmniHuman-1.5对动漫、3D卡通形象都支持,不过效果没有真人照片好。
Q:能生成多长的视频?
A:大师模式最长15秒音频。想更长的可以分段生成,然后在剪映里拼接。
Q:多人对话怎么做?
A:分段生成。第一个人物+音频生成一段,第二个人物+音频再生成一段,最后在剪辑软件里用画中画叠加。
说白了这个东西能干什么
对自媒体创作者来说,最直接的价值就是不用真人出镜。知识博主不想露脸?一张照片配上文案,数字人替你讲。品牌方要做产品演示?上传形象照,选商务风格,几分钟出片。想搞点好玩的?用动漫角色对口型唱歌,整活视频发出去流量不错。
门槛低到什么样?有人用即梦生成的数字人替马斯克讲中文、替《银魂》角色演赵本山小品,虽然效果说不上完美,但已经够让人惊讶了。
当然也有局限。15秒时长限制、某些角度和动作会崩、声音克隆质量参差不齐。但考虑到这是完全免费就能用的东西,性价比已经很高。


 闽公网安备35030302354462号
闽公网安备35030302354462号

